ARC-AGI-1
2019 - Challenges Deep Learning
Links
About
The Abstraction and Reasoning Corpus (ARC-AGI-1) was first introduced in 2019 by François Chollet in his paper On the Measure Of Intelligence. Chollet, a Google AI researcher and creator of the deep learning library Keras, developed ARC-AGI-1 specifically as a novel benchmark designed to test the ability of AI systems to deal with reasoning problems they had not been prepared for.
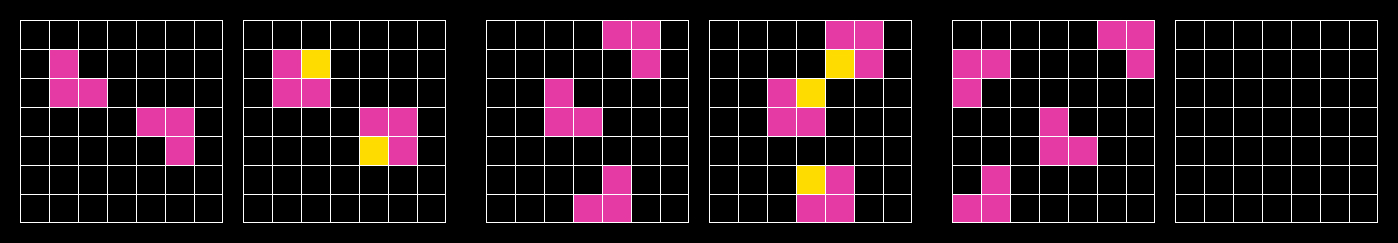
ARC-AGI-1 Task (#3aa6fb7a)
At the time of its launch, there was growing recognition that deep learning methods excelled in narrow, specialized tasks but fell short in demonstrating human-like generalization. ARC-AGI-1 was a direct response to this gap, aimed at benchmarking the skill-acquisition capability (the fundamental core of intelligence) rather than performance on any single, predefined task. It specifically assesses how efficiently an AI can learn and generalize from minimal information, reflecting a fundamental characteristic of human intelligence. For further reading on this, see the ARC Prize 2024 Technical Report.
ARC-AGI-1 consists of 800 puzzle-like tasks, designed as grid-based reasoning problems. These tasks, easy for humans but challenging for AI, typically provide only a small number of example input-output pairs (usually around three). This requires the test taker (human or AI) to deduce underlying rules through on-the-fly reasoning rather than brute-force or extensive training.
| Dataset | Tasks | Description |
Training Set | 400 tasks | A training set dedicated as a playground to train your system |
Public Eval Set | 400 tasks | Used to evaluate your final algorithm. |
| Semi-Private Eval Set | 100 tasks | Introduced in mid-2024, this set of 100 tasks was hand selected to use as a semi-private hold out set when testing closed source models. |
| Private Eval Set | 100 tasks | Used as the basis of the ARC Prize competition. Determined final leaderboard in 2020, 2022, 2023, and 2024. |
From its introduction in 2019 until late 2024, ARC-AGI remained unsolved by AI systems, maintaining its reputation as one of the toughest benchmarks available for general intelligence. The fact that it stayed unbeaten for so long, despite a 50,000x scaleup of base LLM pretraining, highlights the significant gap between human and base LLM capabilities.
In December 2024, OpenAI featured ARC-AGI-1 as the leading benchmark to measure the performance of their o3-preview experimental model, one of the first examples of the Large Reasoning Model (LRM) paradigm that reshaped AI capabilities throughout 2025. o3-preview at low compute scored 75% on ARC-AGI-1 and reached 87% accuracy with higher compute. ARC-AGI-1 was at the time the only benchmark to precisely spotlight the advent of frontier AI test-time reasoning. To view ARC-AGI results on the publicly released o3 model, see our analysis.
This achievement represented a step change in AI's generalization abilities, validating the ARC benchmark's effectiveness in measuring meaningful progress toward AGI. The solving of ARC-AGI-1 triggered renewed interest in benchmarks like ARC-AGI-2, designed to further challenge AI and advance research toward genuine human-level intelligence.